A tale of latency and broken windows
Latency can get out of control because of small day to day changes. Dedicate a small amount of time to think about latency when making changes to keep it under control. parallel I/O, pre-fetching, and avoiding I/O are some simple techniques you can use.
Latency and its importance
As a software developer you might be familiar with the following table:
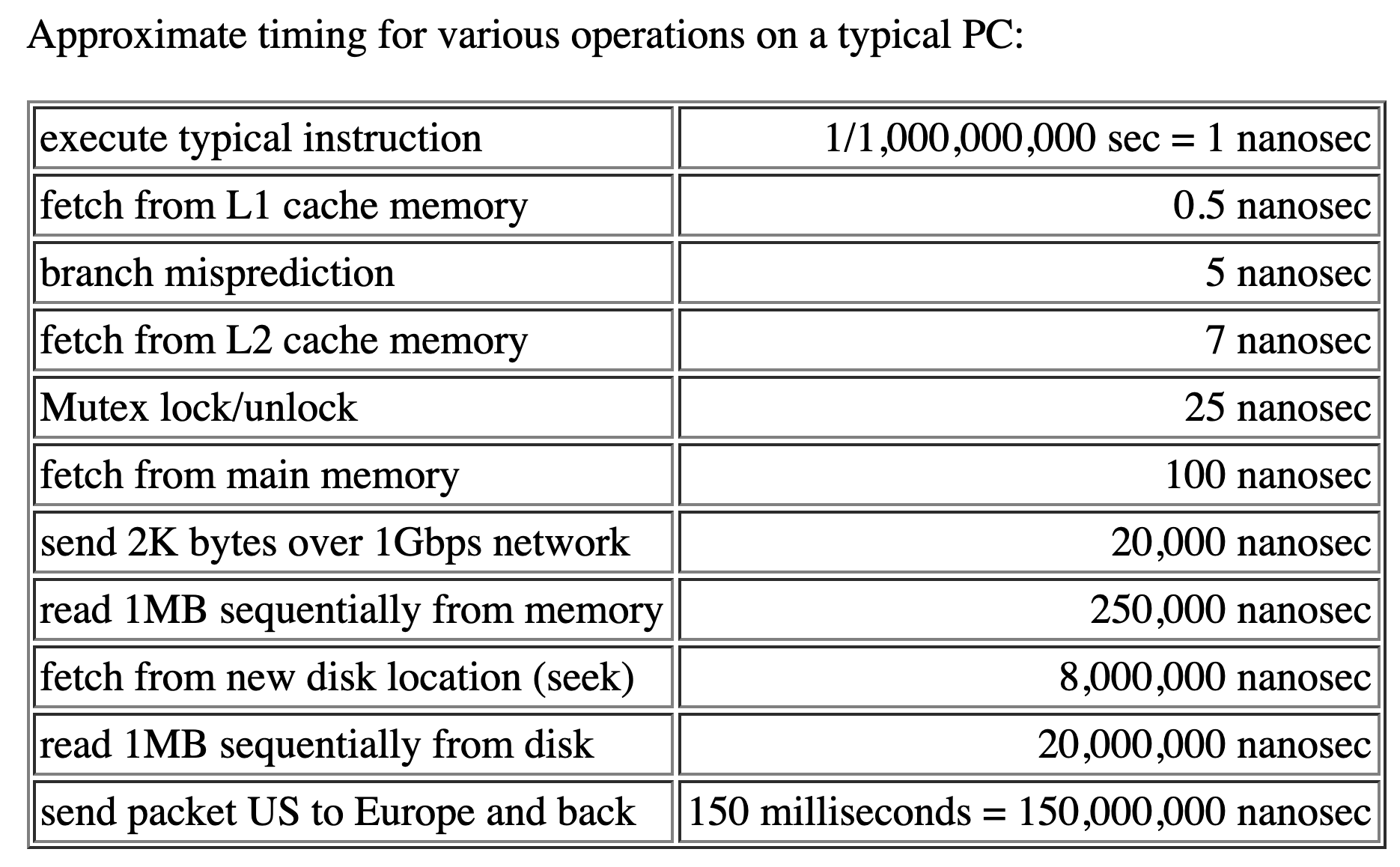
Even if the times are not exact and up to date for 2020, the gist of it is clear. Some operations (disk, network) are more expensive than others. When looking to minimize latency, start from operations that are more likely to take longer, because they are naturally slower due to hardware and speed of light limitations.
The importance of latency will depend on the software you are writing. For some software latency can business critical:
- Real-time computing where operations must guarantee completion under a deadline.
- A SaaS with latency SLAs that you need to meet for your enterprise customers
- e-commerce that loses money when the site is slow (see this great blog post about Amazon).
You might also be writing software that you want to be "fast enough" or "not unnecessarily slow".
Latency and broken windows
While getting to concrete latency guarantees for critical cases requires a lot of work and investment, it is also true that latency is one of those things that is easy to overlook unless you are paying attention. Over time, small decisions can pile up and you can end up with a product that is a lot slower than it should be mostly because of accidental complexity, not essential complexity.
The "broken windows" theory presents the problem in a nice way (From wikipedia): The broken windows theory is a criminological theory that states that visible signs of crime, anti-social behavior, and civil disorder create an urban environment that encourages further crime and disorder, including serious crimes. The theory suggests that policing methods that target minor crimes such as vandalism, loitering, public drinking, jaywalking and fare evasion help to create an atmosphere of order and lawfulness, thereby preventing more serious crimes.

Whether the theory is correct or not (there is an interesting chapter on this in the book Freakonomics) it is a useful context to talk about software. In the software industry, the Pragmatic Programmer book states "don't live with broken windows". If we apply this to latency it is easy to reason that if you let small decisions/changes increase latency, over time the latency of the system will continuously increase over time. At some point, going back and figuring things out will be overly complex and sometimes teams decide to go for complicated solutions to solve this problem. We want to avoid that.
Some real-life examples
One of the things we do at Auth0 is iterative delivery. Initial versions of code work and are tested, etc., but until we validate features with customers we avoid investing in optimizations.
However, some things can be done in an initial implementation so we don't need to optimize later, as that's when as a developer you have the context about what you are doing. Re-thinking many small decisions a few weeks down the road is less than ideal. In this context, thinking about "expensive operations" latency wise is useful.
As part of a project, we are working on developing a new service (new-service) and adding some calls to it from an existing service (client). As we reviewed the changes we made to the client with the team, we found several opportunities for improvement.
The code snippets below are examples written using Javascript, but these ideas are language agnostic.
Parallel I/O
When I/O ops do not depend on each other and you need all data if possible use parallel queries.
Let's say a change to client code looked like this:
const a = await callExistingService(...);
+ const b = await callNewService(...);
+ // do something with a and bThe getDataFromNewService(...) call performs network I/O. Because we are working on this new-service, we know it also does more network I/O to talk to a database (which might need to do some disk I/O). All of these operations are naturally in the slow end of the spectrum from the table at the beginning of this blog post.
If we can't avoid the operations, performing these in parallel yields some clear benefits. If the resulting code looks like this:
const [a, b] = await Promise.all([
callExistingService(...),
callNewService(...)
]);If we call the time for these operations t1 (existing-service) and t2 (new-service), in the last example we change the latency from sum(t1, t2) to max(t1, t2). That even means that if we don't want to make latency higher than the original, all we need to do is ensure t2 <= t1!
Pre-fetching
When I/O operations op2 only runs if op1 is likely to be successful, if op1 is likely to be successful in most cases, consider doing op2 in parallel (pre-fetching).
This case is similar to the previous one, but might be easier to miss. Let's say the code after the change looks like this:
const param = ...
const exists = await callExistingService(param);
if (!exists) {
// handle edge case
}
+ const b = await callNewService(param);
+ // do something with bBoth function calls depend on param, which is available before calling callExistingService(param). If the likelihood of exists being false is low, then calling callNewService(param) in parallel is likely worth it. You won't be adding a lot more load to new-service in case exists === false, but you will be getting the aforementioned benefits for parallel I/O.
The latency improved code would look like this:
const param = ...
const [exists, b] = await Promise.all([
callExistingService(param),
callNewService(param)]);
if (!exists) {
// handle edge case
}
// do something with bNo-op
When you can replace an I/O operation for a no-op, do it.
The best performance/latency optimization is a "no-op", i.e. figuring out how to prevent the call from happening. A simple way of doing this is caching. However, it is important to consider that caching does not need to be overly complicated and require every developer's favorite hammer Redis. It just means to store the value of computation to prevent performing the computation again.
The code we reviewed was doing this:
// somewhere
const context = await hydrateContext();
...
// later
+ const result = callNewService(context.param);In this situation, the client had a way to store the result of a previous call to new-service that returned the same value. If result is relatively small and does not change it can be stored with the context and loaded as part of hydrateContext(). That way, the call we can simply avoid callNewService(context.param);.
The fastest call is the call that never happens 😆
Conclusion
When you are working on code, don't optimize prematurely. I recommend, however, you add a "mental checklist" item to focus on latency and cross it off before submitting a PR. That will help you find Donald Knuth's 3%.
It is likely that just doing that and focusing on that latency for 10 minutes might point to small but valuable improvements that you can make, and accumulating latency over time.
Don't live with latency broken windows!